project by Sean O’Connor, Stephanie Yu, Georgia Kenderova, and Lucky Lim
Video presentation

Click the image to view on YouTube
Abstract
The automated diagnosis of Myocardial Infarction (MI) in 12-lead Electrocardiograms (EKGs) could extend the proven lifesaving benefits of pre-hospital MI detection to many Emergency Medical Services (EMS) systems currently without them. While neural networks have been developed that accurately diagnose MI, such networks are difficult to deploy in clinical practice due to operating on digitized signal data rather than images of EKG waveforms, of which no large publicly available dataset exists. We create such a dataset by plotting digitized EKG records from the Physionet PTB-XL dataset to simulate images of 12-lead EKG printouts. We then train a FastAI Convolutional Neural Network (CNN) learner on the resulting dataset, comparing the accuracy of different network architectures and hyperparameters. We also attempt to train a Recurrent Neural Network (RNN) by inputting individual images of each EKG lead separately. Our results include the generation of a dataset containing 21,837 simulated 12-lead EKG images labeled as “MI” or “Normal”, along with a version augmented with simulated shadows, an alternative version plotted directly with MatPlotLib, and a final version containing each lead in a separate image for use in an RNN. Our trained CNN classifies this dataset achieves an accuracy of 90%, sensitivity 72%, and specificity of 83%, while our RNN fails to train successfully. Similar accuracy is achieved on both the augmented dataset with shadows and alternate directly plotted version. These results show the ability of a CNN to detect MI in images of 12-lead EKGs, indicating the potential for developing a CNN-based application to automatically perform such detection in clinical practice. While the sensitivity of our trained model is not yet high enough for clinical use, our generated dataset allows future researchers to develop techniques improving on our results. It is our hope that such efforts will eventually lead to the development of an model trained on real EKG images that can be deployed in EMS systems to substantially reduce mortality for MI patients.
Introduction
Heart disease is consistently the number one cause of death in America, and 805,000 heart attacks occur in the US annually. [1] Effective heart attack treatment relies on rapid diagnosis through 12-lead EKG in order to minimize the time to reperfusion therapy, and one of the largest improvements in the speed of diagnosis and treatment has been achieved through pre-hospital EKG analysis by EMS personnel. For instance, one study found pre-arrival EMS identification of ST-Elevated Myocardial Infarction (STEMI) through 12-lead EKG lowered patients’ 30-day mortality rates from 15.3% to 7.3%, and 5-year mortality rates from 20.6% to 11.6%. [2]
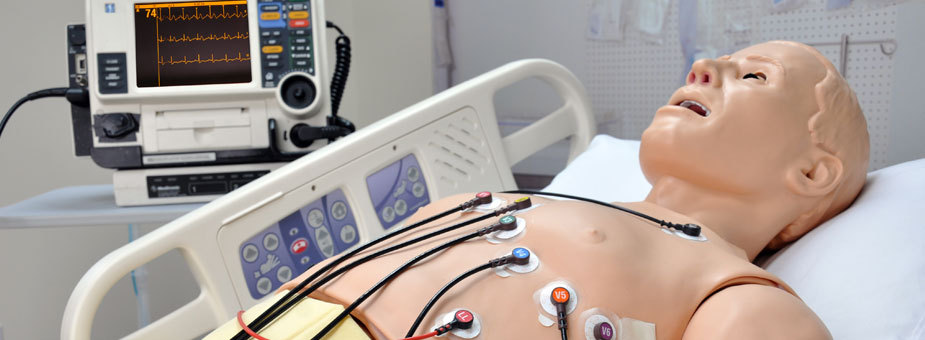
Demonstration of a 12-lead EKG: wires placed on the chest and limbs produce a graph of the heart’s electrical activity over time, seen on the monitor in the background.
Yet despite the well-established lifesaving effects of performing pre-hospital 12-lead EKGs, many EMS systems continue to rely on Basic Life Support-level (BLS) providers untrained in EKG interpretation. For instance, the Detroit EMS system, which handles approximately 100,000 calls annually is predominately staffed by BLS units, and Michigan has a statewide shortage of hundreds of ALS-level paramedics who would be trained to perform EKGs. [3] The result is that MIs go undetected before hospital arrival, resulting in slower diagnosis, slower treatment, and higher mortality.
Paramedics interpreting an EKG before arrival at the hospital.
In such EMS systems where staff trained in EKG interpretation are unavailable, automatic computer interpretation of EKG could potentially fill in the gap to provide the lifesaving benefits of pre-hospital diagnosis to heart attack patients. However, current MI detection algorithms in use on EKG monitors are unreliable. For instance, one study found that a commonly used EMS monitor identified just 58% of STEMIs, missing the diagnosis in the remaining 42% of STEMI patients. [4]
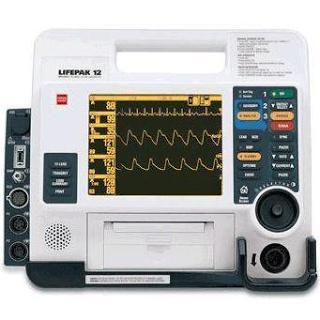
The Lifepak 12, a commonly used EMS heart monitor whose built-in software was found to have only 58% sensitivity in identifying STEMIs.
The past few years have seen researchers achieve breakthrough accuracy levels in automatic EKG interpretation using neural-network based approaches, in many cases rivaling or surpassing the accuracy of clinical providers. [6], [7], [8] However, such algorithms have yet to be widely applied to actual healthcare practice. One barrier to such application has been the fact that all such algorithms to our knowledge have been developed to interpret digital EKG signals, which in the field are only available to software directly interfacing with an EKG monitor. Clinical implementation of such algorithms would either need to be done on proprietary software run on EKG monitors themselves, or else on hardware with the ability to interface directly with EKG monitors to receive digital signals. In either case, such implementation would be difficult both for researchers and clinical practitioners.
We attempt to resolve this difficulty by testing an alternate approach to neural-network based STEMi detection using images. While digital signals are difficult to directly obtain in clinical practice, EKG monitors are equipped with printing capabilities that are routinely used to record readings. If neural networks can accurately detect STEMis in images of 12-lead EKGs, then such printouts could be used as the basis of classification independently of the specific EKG device. For instance, we envision an image-based approach being the basis of a mobile phone application that would allow providers to easily take a photo of an EKG printout and have it automatically classified. Such an application could be developed by any researchers without needing access to proprietary software, and could be applied in clinical practice by healthcare agencies without needing to purchase specialized equipment. Thus the feasibility of an image-based classification approach for EKGs could represent a large step in bridging the gap between research achievements and clinical practice.
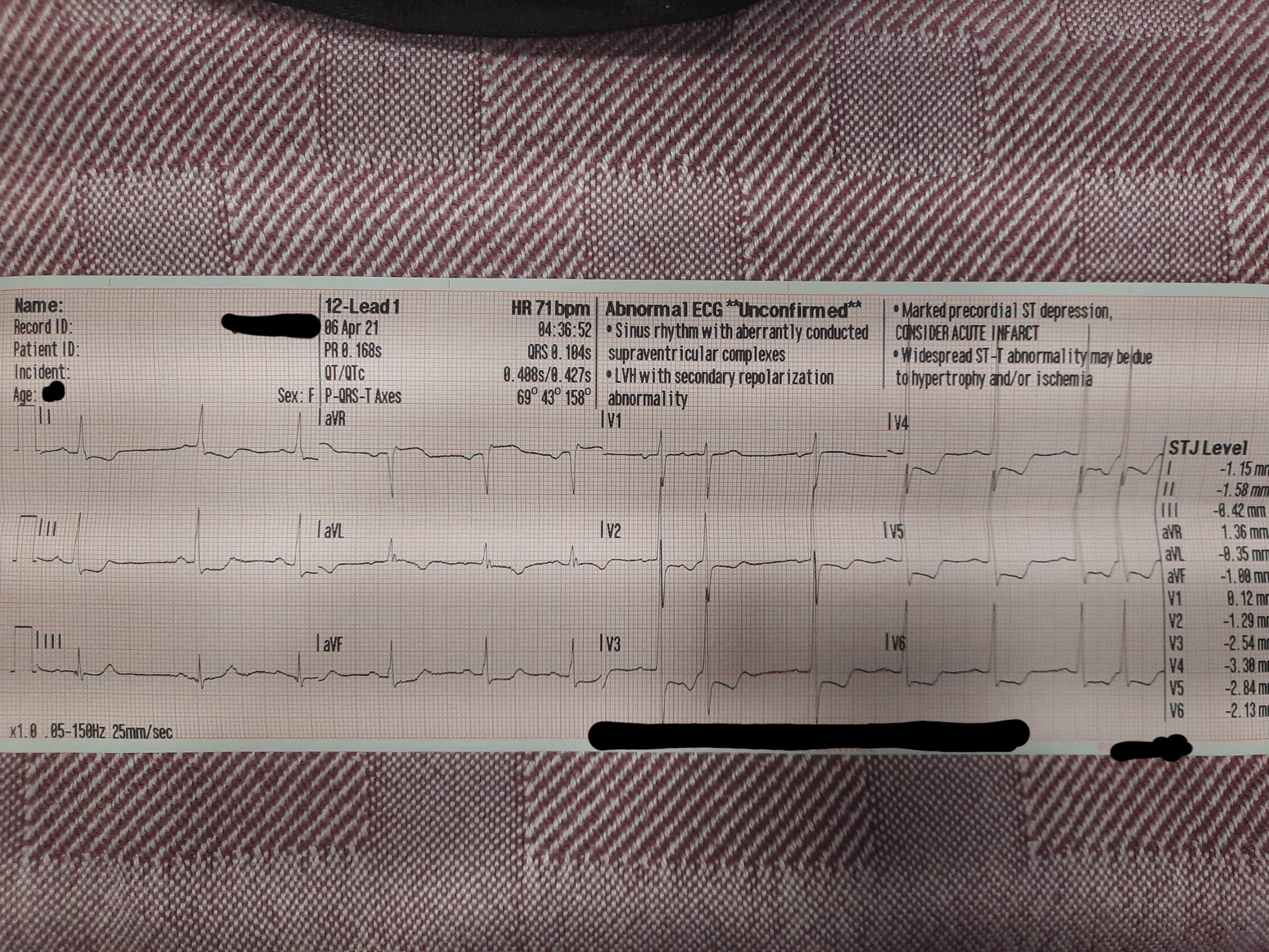
An EKG strip printed out from a heart monitor: healthcare providers typically interpret these strips, rather than a live feed on the monitor.
A challenge to this approach, however, is the lack of a publicly available dataset of annotated 12-lead EKG printouts. To test the feasibility of our approach with publicily available data, we create a dataset by plotting each lead of digital signal-based readings and combining the plots from each lead into a single image. The result is images that approximate 12-lead EKG printouts.
Another substantial challenge is the fact that, depending on the part of the heart affected by MI, diagnostic features such as ST-elevation can appear in different leads and thus different parts of the image. This fact requires our neural network to recognize these features regardless of their location. Furthermore, even baseline EKGs can look dramatically different from patient to patient due to a wide varieties of arrhythmias and the routine presence of noise in readings caused by electrical fluctuations and patient movement during the procedure. We attempt to overcome these challenges by training on a large and diverse dataset.
Our finished neural network achieves a high level of accuracy, suggesting the feasibility of automatically classifying EKGs through images of printouts. While our trained network’s sensitivity still requires improvement, techniques from prior MI classification studies can likely be employed to make such improvements in future work. These results support the development of an application for computer STEMi recognition that can be easily integrated into clinical practice, and suggest that such an application can extend the lifesaving benefits of pre-hospital EKG interpretation to patients currently unable to receive it.
Ethical concerns for our project include potential biases in our dataset, which could influence our model’s performance and thus patient outcomes. Testing an application based on our model in clinical practice will also raise ethical concerns due to not only concerns for patient safety, but the difficulty of obtaining high-quality informed consent from patients suffering from an acute MI. Finally, the use of neural networks to make clinical treatment decisions raises broader concerns about the influence such practices may have on healthcare system design and practice.
Related Works:
In this section, we will discuss relevant research pertaining to the application of neural networks to STEMi detection in EKGs. Past studies using convolutional neural networks (CNNs) have achieved high accuracy and sensitivity classifying STEMi’s from various sets of leads. A study using 4-lead EKGs, sub-2d convolutional layers, lead asymmetric pooling layers to combine data from the multiple leads to achieve a 96% accuracy classifying Anterior STEMis. The algorithm’s real-time performance was tested on a lightweight embedded system and found to be suitable for application in EKG wearable technologies. [7]
A study more pertinent to our project’s scope combines image-based deep learniing techniques to improve detection accuracy of an important marker for detecting myocardial ischemia in EKGs: a ST depression change. The CNN created yields an average AUC at 89.6% from an independent set, a mean sensitivity rate at 84.4% and a specificity at 84.9% at selected optimal cutoff thresholds. [9]
Another study using a CNN and 12-lead EKGs, proposed a performance optimization technique through two data pre-processing methods: noise reduction (notch filter and high pass filter) and pulse segmentation (via QRS complex detection). The preprocessing techniques improved the sensitivity, specificty, and area under the curve (AUC) of the receiver operatnig characteristic (ROC), enhanncing STEMi detection performance on a 275 EKG record dataset with 179 STEMis and 96 normal. [8]
Due to the complexity of classifiers like CNNs and other neural networks, key decision makers like physicians and experienced clinicians stigmatize the black-box nature of neural network-based diagnoses. A more recent study using a ML fusion model consistening of Logistic Regression (LR), Artificial Neural Network (ANN), and Gradient Boosting Machine (GBM) and modified approach using 554 temporal-spatial features of 12-lead EKGs from a sample size of 1244 patients was able to achieve a 52% gain over commercial software ad 37% gain over “experienced” clinicians. From the study, the researchers concluded that linear classifiers like LR are just as effect as ANN, which lends the use of linear classification favorability in clinical practice [10]
Methods
Dataset Generation:
To generate our image datasets, we use the PTB-XL dataset[11], [12], a collection of 21,837 labeled EKG records published by Physionet [13]. 5,486 (25%) of these EKGs are labelled as indicating Myocardial Infarction, while the remainder are either labelled Normal (9,528 / 44%) or as displaying a different abnormality not indicative of Myocardial Infarction (7,326 / 34%); for our purposes, we consider both of the latter to be “Normal”. Each file is a digital recording of electrical activity in 12 standard ECG leads over 10 seconds, as would typically be seen in the emergency setting when diagnosing Myocardial Infarction. While the initial recordings were made at 500 Hz, the dataset also offers versions downsampled to 100 Hz, which we use throughout this study due to its closer resemblance to the frequencies measured by heart monitors in emergent clinical practice.
We create an initial dataset by using Physionet’s WFDB-Python library to read the numerical data from each record into a 12x1000 numpy array. We then plot the 1000 numerical data points from each lead with Matploblib. We transform the resulting plot into a 512x512 pixel grayscale image with OpenCV, then after repeating this process for all 12 leads we concatenate the resulting images into a 3 x 4 grid. The result is one 2048x1536 PNG image displaying all 12 leads for each patient (see figure in discussion). We use pandas to extract labels from a CSV file in the initial dataset and move each image to a parent directory indicating its label as “mi” or “normal”; the result is “Dataset 1”.
Iterating on our first generation efforts, we then generate a second dataset by using WFDB-Python’s plotting functions instead of directly passing numerical data to Matplotlib. We enable an option in these functions to draw a background grid similar to those typically seen in EKG printouts. We modify the source code of the WFDB plotting functions to allow the editing of the resulting figure with Matplotlib, then standardize the vertical limits of each plot’s display and remove figure features such as tick marks, legends, and axes labels. The result is 640x480 PNG images. As before, each file is moved to a parent directory indicating its label, resulting in “Dataset 2” (see figure in discussion).
We then take our second dataset and attempt to augment our initial data to simulate an irregularity commonly seen in mobile phone photographs of EKG printouts: shadow overlying the image. We use the Automold Road Image Augmentation Library to randomly add between 1 and 3 5-vertex shadows to each image in Dataset 2. We save the results as new images, resulting in “Dataset 3” (see figure in discussion).
Finally, to test the classification of our images using an RNN, we generate a fourth dataset with each lead in its own 512x512 image. We use the same methods as for Datset 1, except stopping after generating a figure of each lead with Matplotlib. No transformation is applied with OpenCV, nor are the images concatenated together. The result is 12 images for each patient plotting each of the 12 EKG leads separately, making up “Dataset 4” (see figure in discussion).
CNN Training
We developed our model as a FastAI cnn_learner, which employs transfer learning from pre-trained ResNet models and is subsequently fine-tuned on our dataset. We employed the built-in functions error_rate, recall, precision, and F1 score as our validation metrics. We used a FastAI dataloader to randomly split our dataset into training (80%) and validation (20%) portions, as well as apply a set of data augmentations that perform rotation, warp, and lighting transformations on our images. We disabled horizontal flipping in these transformations, as EKG waveforms are horizontally asymmetric and will never appear horizontally flipped in real images.
We started development with hyperparameter tuning, testing different resnet architectures and batch sizes. We performed training for these tests on a subset of 1,554 images from Dataset 2: 777 labeled “Normal” and 777 labeled “MI”. All tests were run for 29 epochs, the amount at which we no longer observed any decrease in loss during an initial trial training.
To figure out which reset provides the best results, we trained the model using resnet18, resnet34, resnet50, resnet101, and resnet152 while controlling batch size at 16. We then used the best-performing architecture (resnet 152) and tested batch sizes 4, 8, 16, and 24. Higher batch sizes resulted in RuntimeError: CUDA out of memory when tested with resnet 152. Thus, we also used smaller architectures to include trials of higher batch sizes: we tested batch size 32 using resnet 50, and batch sizes 64 and 128 using resnet 34.
After finding the optimal hyperparameters, we then perform final trainings for 25 epochs on the entirety of Dataset 2 using the 4 combinations of our best 2 batch sizes (8, 16) and resnet architectures (50, 152). We then trained a model using resnet 50 and bs 16 on Dataset 3 to test the classification of images with shadows. Finally, for comparison, we also trained a model on Dataset 1 using resnet 18 and batch size 16; a smaller resnet was required due to the larger size of these images resulting in an out of memory error with any larger architecture.
RNN Training
To contextualize the performance of our CNN, we felt compelled to build and train another type of neural network. Ultimately, we decided on the RNN, which is distinguished by its memory capacity — when generating outputs, it recalls things learned from prior inputs. We believed that such a quality would be relevant to EKG classification, as Myocardial Infarction EKGs often contain complementary ST manifestations on the different leads (i.e., an ST elevation in one lead is coupled with an ST depression in other), and we hypothesized that a NN model with the ability to recall characteristics of previous leads would have an upper hand in MI diagnosis.
The RNN training dataset was adapted from Dataset 4: we converted each patient’s 12 lead images (i.e., the images in each subdirectory of Dataset 4) to tensors and stacked them, producing one tensor for every patient. Then, we saved each resulting tensor in a file and added a corresponding mi or normal label.
To create the RNN, we first adapted a Pytorch implementation of a Convolutional LSTM (https://github.com/ndrplz/ConvLSTM_pytorch), specifying one LSTM layer, 10 hidden layers, and a kernel size of 3. Next, we used Pytorch to flatten the LSTM layer to a single tensor, before applying a linear transformation and a sigmoid activation function. For the RNN training process, we selected Binary Cross Entropy for our cost function, Adam for our optimization algorithm, two for our batch size (to accommodate our GPU memory constraints), and ten for the number of epochs.
Discussion
Datasets
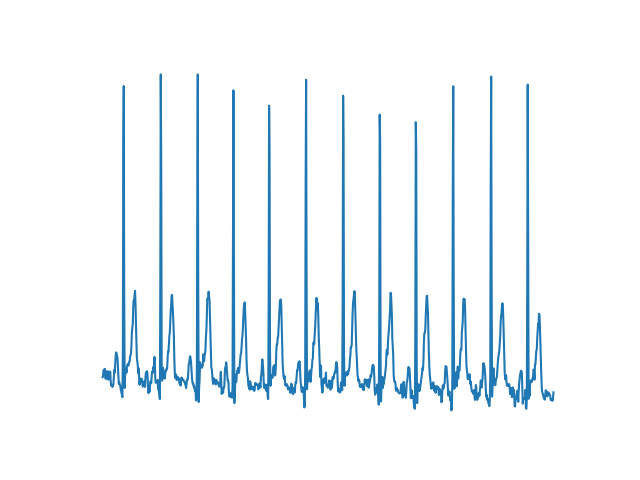
Our first generated image dataset successfully plotted EKG waveforms and allowed training of a CNN; however, the generated images bore several striking differences from real-world EKG printouts (see figures below). First, many images in our dataset show repeated large positive or negative vertical spikes not seen in normal EKG printouts. While EKG waveforms do contain various peaks and valleys, these also exist in our dataset and bear a distinct shape from the spikes, which instead seem to be the result of single very high or low outlier data points. EKG readings always contain some amount of noise or artifact, which may be the source of such outlier data points. Other studies classifying EKG data have pre-processed data with notch or high-pass filters, which would remove extreme outliers; it’s possible that clinical EKG monitoring equipment employs similar techniques that prevent such spikes from displaying on printouts.
The images in dataset 1 are also significantly more choppy than typically seen in real EKG printouts. This can partially be explained by the sampling resolution of our data, which at 100 Hz is significantly higher than resolutions in the 40-60Hz range recorded by many clinical monitors; the result is less “smooth” lines as more fine-grain details of the waveform are captured. It’s also possible that other pre-processing techniques to smooth data are used by clinical equipment, in order to reduce the effects of noise and make waveforms easier for humans to read. Other notable differences include the lack of a background grid in our images and the separation of each lead by a significant amount of whitespace.
Despite these differences, however, the fact that a CNN was able to classify these images with 89% accuracy indicates that these images successfully visualize the important diagnostic features in each record. As such, the dataset successfully serves its purpose as a proof of concept for image-based classification of EKGs, despite its lack of realistic representation of the sort of images we were hoping to simulate.
Fig. 1: Image from Dataset 1
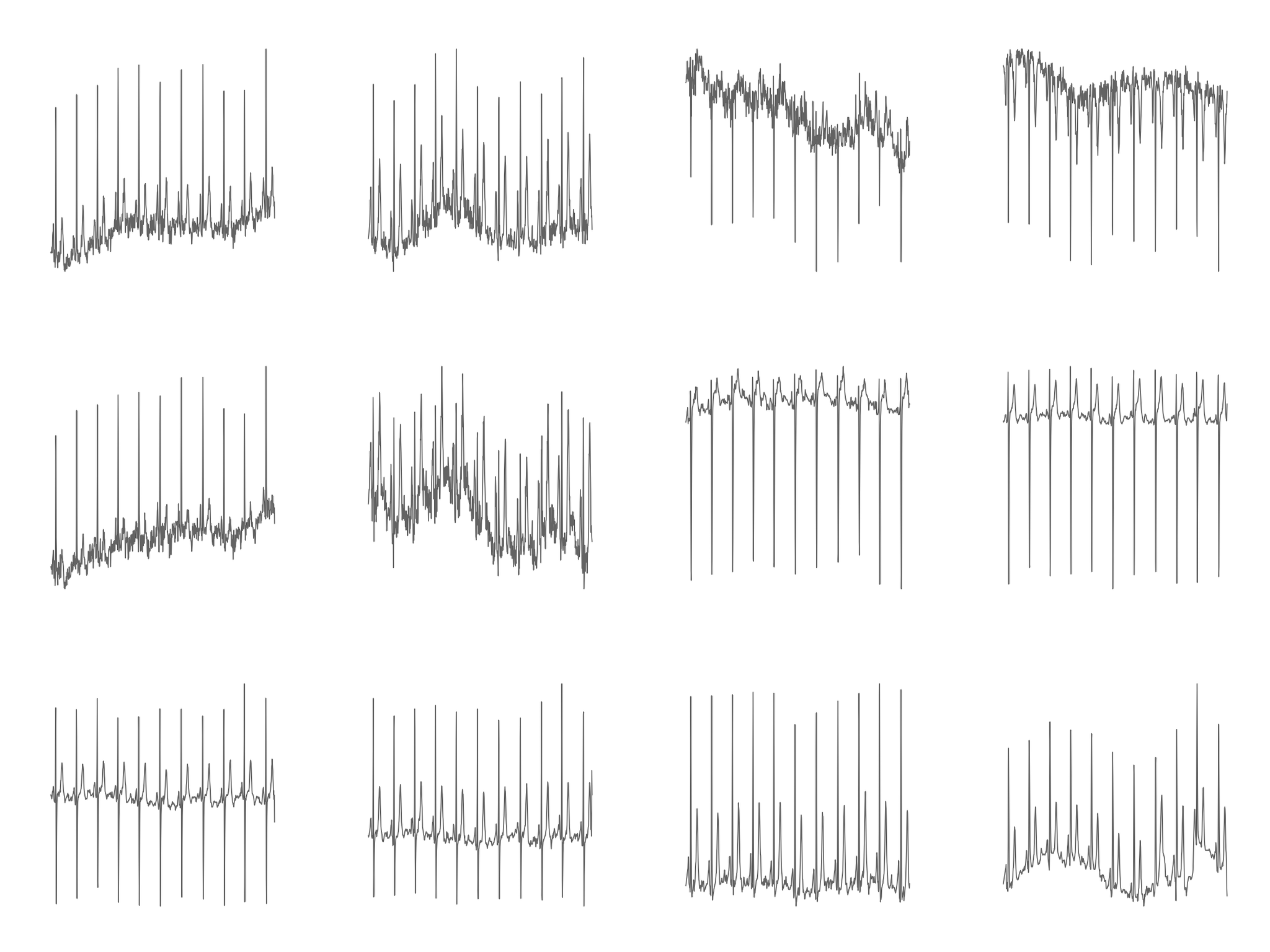
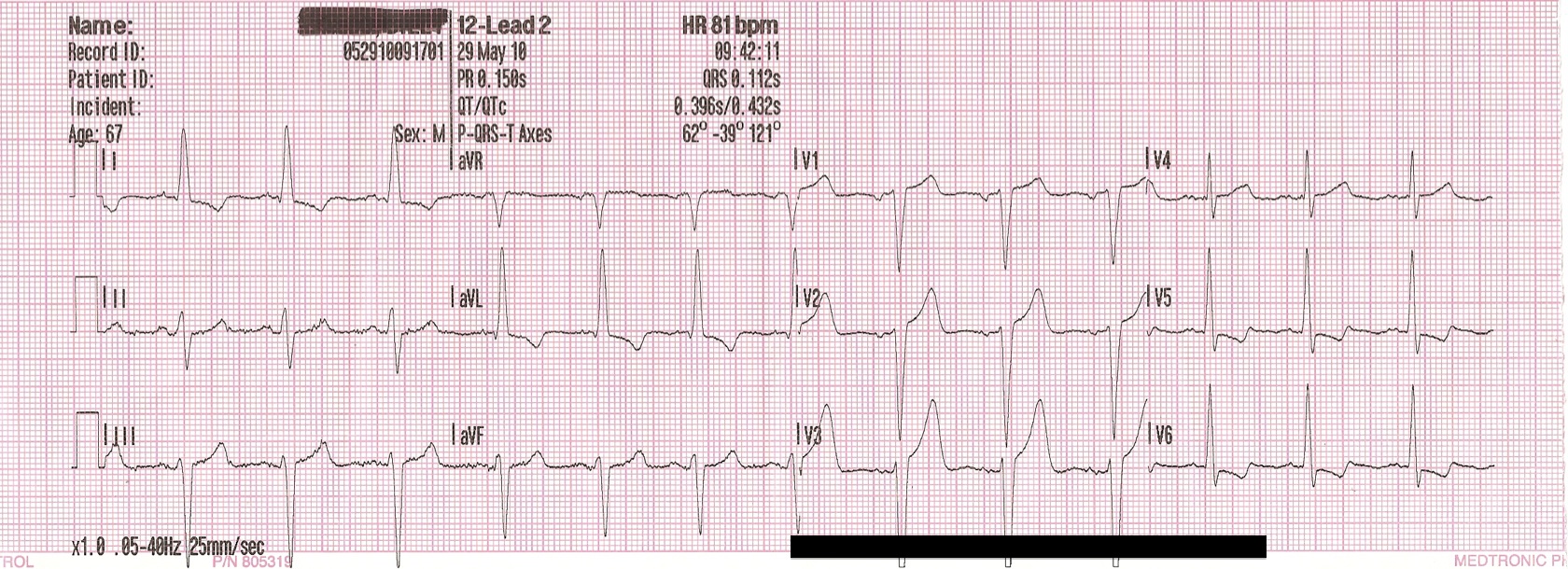
Fig. 2: Image of real EKG printout for comparison
Our second dataset addresses many of the issues with the first by utilizing the WFDB library’s plotting functions, which eliminates both the large vertical spikes and much of the choppiness in the original images. Not only does this dataset produce smoother and more realistic looking waveforms, but it also adds a background grid and removes most of the excess whitespace separating images. However, dataset 2 did introduce a separate issue in the layout of each lead in the image. While real EKG images are typically arranged in a 3 x 4 grid, these images vertically stack all leads in a single column. We opted not to horizontally concatenate the leads from each image in this way due to finding that each plot was substantially wider than typically seen in EKG printouts, possibly indicating the 10-second samples in our data represent a longer timespan than is usually captured in a single printout. While we considered taking a narrower subset of the image, doing so could possibly result in removing the section of the EKG where the key diagnostic features determining it as an MI are present. Without beaty-by-beat annotation of our dataset, we opted to leave the images in a one-column format. Again, this dataset was able to be classified with 90% accuracy by a CNN, indicating that it successfully visualized key diagnostic features and serves as proof of concept for image-based EKG classification.
Fig. 3: Image from dataset 2

Our augmentation in the third dataset successfully simulated one of the most common distortions present in real pictures of EKG printouts: shadow overlaying the image. While the shadows produced aren’t entirely realistic, they do provide a good test for the sort of artifact a classifier would have to overcome on EKG images captured during clinical practice.
Fig. 4: Image from dataset 3
Fig. 4.5: Shadows on real EKG images for comparison
Finally, our fourth dataset generated individual lead images similar to those that might be captured by photographing part of an EKG printout at a time. These allowed us to feed sequential images into an RNN to test the performance of such a network on MI classification.
Fig. 5: Image from dataset 4
Hyperparameter Tuning
Before analyzing the results, let’s first define the metrics used to assess the impact of our hyperparameter tuning on performance:
- Error rate provides a measure of general misclassification. It denotes the proportion of cases where the prediction is wrong (i.e., misclassification of MI EKGs as normal EKGs and vice versa).
- Recall_score provides a measure of missed MI predictions (i.e., misclassification of MI EKGs as normal EKGs). It denotes the number of correct MI predictions made out of all possible MI predictions, and is most commonly used to minimize false negatives.
- Precision provides a measure of correct MI predictions. It computes the ratio of correct MI predictions to the total number of MI predictions, and is most commonly used to minimize false positives.
- F1_score provides a single measure of both recall and precision, and is calculated via this formula: (2*recall_score*precision) / (recall_score*precision).
Fig. 6: Comparison of Resnet Architectures
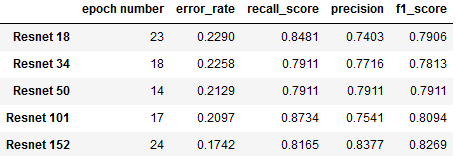
This chart summarizes our findings from experimentation with different variants of ResNet architecture (each distinguished by its number of layers). For each architecture, metrics were recorded from the epoch with the lowet validation loss:
- Resnet 152 shows the lowest error rate (17.4%), along with the highest precision (83.77%) and F1 score (82.69%)
- Resnet 101 achieves highest recall (87.34%) along with the second best error rate (20.97%), at the expense of having the lowet precision (75.41%).
- Resnet 50 achieves an only negligibly higher error rate than 101 (21.29%), along with more balanced recall (79.11%) and precision (79.11%) scores.
As it appears to have the best overall performance, we decided to pursue further hyperparameter tuning with ResNet 152 while finding the optimal batch size. Batch sizes above 24 had to be tested with a smaller resnet architecture due to memory limitations. The following table captures our findings:
Fig. 7: Comparison of Batch Sizes
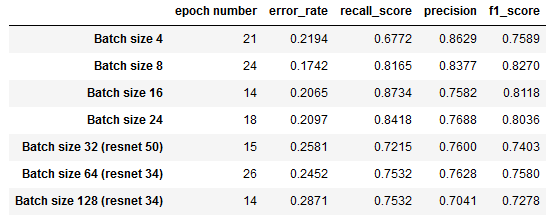
We can observe that a batch size of 8 minimizes error_rate and maximizes f1_score, while a batch size of 16 corresponds to the best recall_score and second lowest error rate.
Final results
We then used two of our best-performing ResNets, ResNet 50 and ResNet 152, and batch sizes, 8 and 16, to conduct four trials on the full Dataset 2. Based on the trends we observed in which epoch produced the best results during hyperparameter tuning, we reduced the number of training epochs to 25.
Fig. 8: Results training on full datset
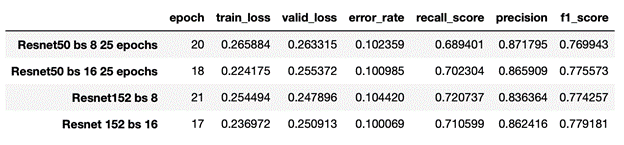
The data indicates that the best-performing hyperparameter combination is ResNet 152 and a batch size of 16, as the model with this combination yields the best values for our two most important measures of performance, error_rate (10.01%) and f1_score (77.92%). Notably, this model can distinguish MI EKGs from normal EKGs with 89.99% accuracy! It is worth noting, however, that each of the four combinations achieved significant classification success: from trial to trial, we can observe that the differences in both metrics are nearly negligible.
It’s also important to note that the recall score, 70.2% ,is substantially lower than the overall accuracy. Our dataset contains a larger portion of normal EKGs (66%) than MI (34%); as such, classifiers don’t necessarily need to detect MI with a high level of sensitivity in order to achieve a good overall acuracy. For instance, consider a hypothetical classifier that labeled every EKG as normal: despite missing every MI, such a classifier would still have an accuracy of 66%. The fact that recall is 20% lower than accuracy seems to indicate our model is somewhat biased towards labelling EKGs as normal, which in a model whose purpose is to detect MI is less than ideal. Thus, the recall and F1 scores are perhaps ultimately a better metric of our model’s success.
Fig. 9: Training loss on full Dataset 2
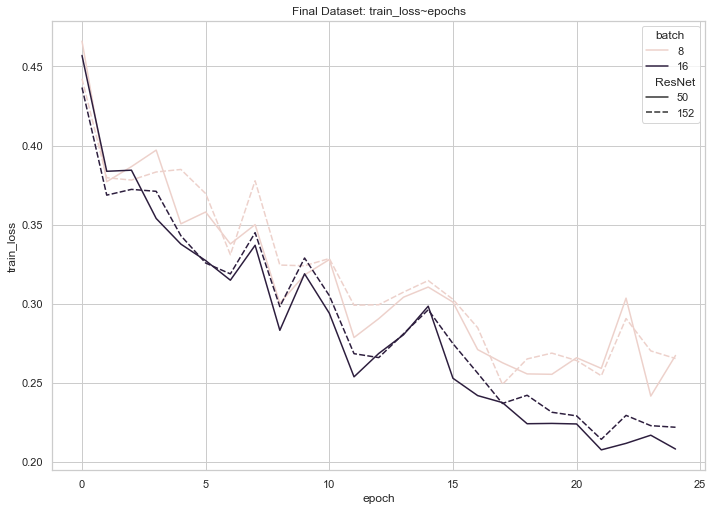
Fig 10: Validation loss on full Dataset 2
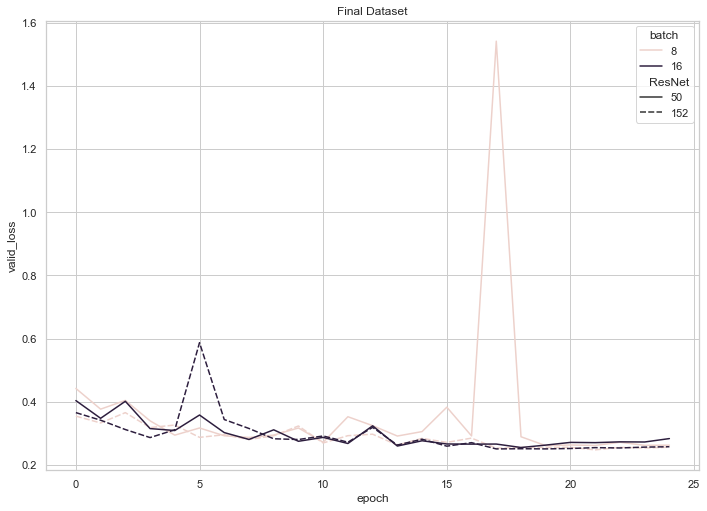
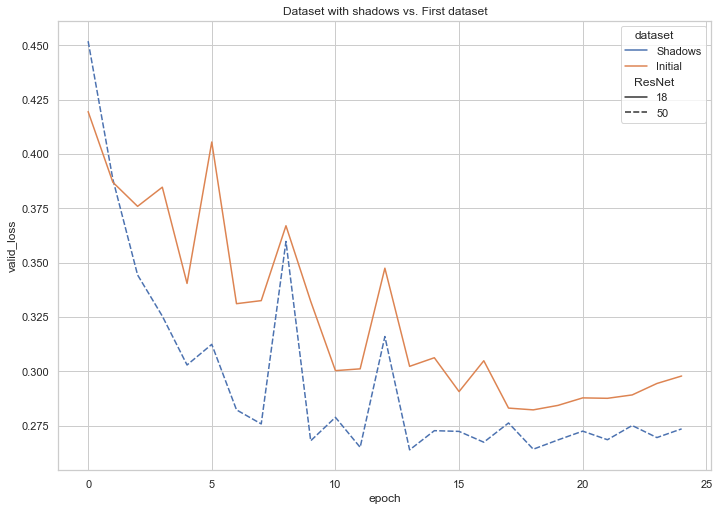
According to these graphs, training loss for each of our four final models trended downwards until the 20 epoch mark, where it began to plateau or even experience a slight increase. Validation loss, on the other hand, experienced consistent, shallow decreases until the 20 epoch mark (with the exception of an unforeseen spike at 17 epochs for the ResNet 50 with a batch size of 8), where it began to plateau or trend upwards. These observations (namely, the decreasing training loss coupled with an increasing validation loss) enabled us to conclude that training each model beyond 20 epochs may have resulted in slight overfitting.
As an addendum to our explorations, we investigated the performance of our best-performing model on Dataset 3 (an augmented version of our dataset, in which shadows overlay a portion of the images). The following graph captures the decline of training loss that corresponded with the increase in number of epochs and reveals the successful learning that our model underwent.
Fig. 11: Training loss on Dataset 3 (images with shadows)
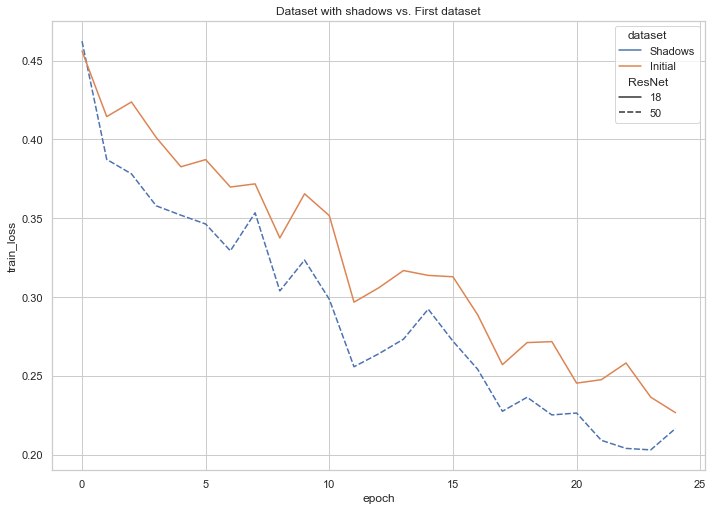
Fig. 12: Validation loss on Dataset 3 (images with shadows)
We also trained a model on Dataset 1, the more roughly-plotted version made directly with MatPlotLib. The following compares the results from each of our three datasets:
Fig. 13: Results from Datasets 1, 2, and 3
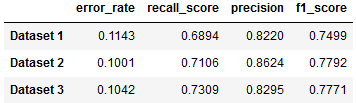
Ultimately, all three Datasets are able to be classified with only a few percentage point difference in accuracy metrics.
RNN Testing
The RNN we created was unsuccessful: we observed that throughout the entirety of the training process, the cost fluctuated drastically from training sample to training sample, rotating among the values of 0.0, 50.0 and 100.0. Since the training cost exhibited no decreasing or stabilizing patterns, we conclude that our RNN failed to learn.
Overall results
Our CNN results suggest the feasibility of image-based EKG classification, although also pointing to the need to augment transfer learning with problem-specific techniques in future work. While our classifier achieves 90% accuracy, its sensitivity of 70% is not yet high enough for clinical application, where the acceptable error rate is very low. Missing an MI could result in lack of treatment that could potentially cause outcomes up to death, while false positive diagnosis could potentially subject a patient to unnecessary invasive procedures with similarly severe consequences. Error rates in STEMi classification by Emergency Room Physicians are approximately 3% [5], and prior non-image based work has achieved sensitivity as high as 95%.[7] Techniques from this prior work could potentially be used to improve our own results, such as lead pooling and sub 2D convolutional layers[7], and pre-processing images for noise reduction and pulse segmentation[8]. However, our classifier already substantially outperforms general physicians and Emergency Room Residents, who have been found to have accuracy rates of 70% and 68% respectively [6]. It also outperforms the non-neural network based algorithm used in the LifePak 12, one of the most popular devices for pre-hospital 12-lead EKG acquisition by EMS, which one study noted only detected 58% of STEMIs [4].
Furthermore, the fact that we achieved similar results on Datasets 1, 2, and 3 shows the promising ability of a CNN to be resilient in the face of conditions likely faced in clinical application. Pictures taken during clinical practice, especially in the pre-hospital Emergency Medicine environment, are likely to have significant distortions such as variable lighting, shadows on the image, and rotational skew. Furthermore, different heart monitors can produce printouts that vary in factors like scale and layout. Datasets 1 and 3 offer a limited initial look into such variations, and our trials indicate that such factors don’t have to significantly degrade a model’s accuracy.
Ethics
Our work touches on a number of ethical issues and dilemmas, including:
- Who is held responsible in the case where the model’s prediction is incorrect and the diagnosis and treatment lead to an unfavorable outcome for the patient?
- We imagine that our model would be used in situations where the caregiver is not properly trained to read EKGs, so the patient is already put at risk of inaccurate diagnosis. In this specific case, it seems like the neither the model, nor the caregiver should be held accountable, simply because the latter is not trained to read an EKG and hence respond appropriately already, so the addition of our model would technically only improve the rates of accurate and timely diagnosis. If there’s ever an implementation used by medical professionals trained to read EKGs, it seems like they should be the ones responsible, as they are making the final call. In general, our model only analyzes the EKG as accurately as possible, but is not the entity reponsible for the actions taken given this information. To avoid such situations as much as possible, NN models should be implemented in the real world only after certain accuracy is achieved, so that they don’t lead to loss of life and other negative consequences. In any situation where the technology is the one that makes the final decision, the developers and manufacturer/company should be held accountable.
- Issues around collection of sensitive health data - should it be collected in an effort to improve the model? In what way should it be collected?
- Data from the real world would be essential in improving the accuracy of the model. In that sense, it would be helpful to collect such data, even though it is highly sensitive. In order to do that in a more sensitive way, this information should be anonymized and consent from the patient should be obtained (once they are able to give it).
- Does the data used to train the model capture the heterogeneity of the real world? How can a more comprehensive dataset be assembled?
- Most likely the datset we’re currently using is not incredibly diverse. A potential way to address this issue is to partner with hospitals and medical centers around the world to collect data from a diverse group of individuals. This approach introduces several complications, such as what incentive would such institutions have to collect and provide that data; having to navigate different health systems and ways that consent is obtained (would consent obtained in, for example, Vietnam be accepted in wherever the company is situated/headquartered?); and other logistical questions.
- How do we find and remove potential biases in the dataset?
- Similarly to the previous question, we need to make sure that we are gathering data from different parts of the world instead of just one hospital or just one country. Similarly, finding potential biases would require testing the model on a diverse range of data.
- Who benefits from the development and potential commercialization of such a tool?
- The main beneficiary (at least financially) would definitely be the company that owns the product. The introduction of such a technology aims at improving the rates of correct and timely diagnoses and consequently lower the rates of improper treatment or even death. Therefore, a model that is able to accurately read EKGs would also benefit health workers and patients. Additionally, if the model reaches a high accuracy rate, it may even be beneficial for smaller or under-funded hospitals and medical institutions, as it would allow a quick and relatively cheap solution to diagnosing patients. This raises other important ethical questions about technology replacing humans and taking over what could potentially be jobs performed by people.
Addressing these questions in depth is important in assessing the model and making sure that introducing it into the health system will be beneficial and not cause harm.
Reflection
Our work mostly acts as a proof of concept, pointing to the possibility of future work by researchers with access to proprietary EKG image datasets and/or partnership with clinical researchers to confirm the viability of classifying EKG images obtained in real clinical settings. While our goal was to create an app that assists EMTs and other health professionals in quickly and accurately diagnosing patients, we recognize that our current model requires more work and calibration to achieve this. For example, the image dataset that we generated is still not sufficiently similar to real EKGs to train a model that can classify actual pictures of EKGs. While we tried to plot and visualize the data to resemble as closely as possible an actual EKG, improvements can be made. For example, the plot lines can be made to appear black with a red background grid, which is typically the color of EKGs (see Fig. 2); further image augmentation to simulating factors such as lighting may be implemented to mimic real-world pictures; in general, improvements in the visual representation of the data that make it appear more similar to real EKG printouts may lead to lower error rates when the model is tested on real pictures. Ideally, a dataset of real pictures of EKGs can be assembled and used to train the model.
Additionally, further experimentation with adding more and different types of layers to the NN, as well as changing batch size, is needed to achieve the best accuracy-computation cost trade-off. Finally, in an attempt to asses the need for such a tool (as well as its impact), a more thorough understanding of the ethics must be achieved.
Citations
- Virani SS, Alonso A, Aparicio HJ, Benjamin EJ, Bittencourt MS, Callaway CW, Carson AP, Chamberlain AM, Cheng S, Delling FN, Elkind MSV, Evenson KR, Ferguson JF, Gupta DK, Khan SS, Kissela BM, Knutson KL, Lee CD, Lewis TT, Liu J, Loop MS, Lutsey PL, Ma J, Mackey J, Martin SS, Matchar DB, Mussolino ME, Navaneethan SD, Perak AM, Roth GA, Samad Z, Satou GM, Schroeder EB, Shah SH, Shay CM, Stokes A, VanWagner LB, Wang N-Y, Tsao CW; on behalf of the American Heart Association Council on Epidemiology and Prevention Statistics Committee and Stroke Statistics Subcommittee. Heart disease and stroke statistics—2021 update: a report from the American Heart Association [published online ahead of print January 27, 2021]. Circulation.doi: 10.1161/CIR.0000000000000950
- Bång, Angela, Lars Grip, Johan Herlitz, Stefan Kihlgren, Thomas Karlsson, Kenneth Caidahl, and Marianne Hartford. “Lower mortality after prehospital recognition and treatment followed by fast tracking to coronary care compared with admittance via emergency department in patients with ST-elevation myocardial infarction.” International journal of cardiology 129, no. 3 (2008): 325-332.
- Turner, A., Dunne, R. and Wise, K., 2017. National Institute For Health Care Reform. [online] Nihcr.org. Available at: https://nihcr.org/wp-content/uploads/2017/06/NIHCR_Altarum_Detroit_EMS_Brief_5-30-17.pdf [Accessed 8 May 2021].
- Mary Colleen Bhalla, Francis Mencl, Mikki Amber Gist, Scott Wilber & Jon Zalewski (2013) Prehospital Electrocardiographic Computer Identification of ST-segment Elevation Myocardial Infarction, Prehospital Emergency Care, 17:2, 211-216, DOI: 10.3109/10903127.2012.722176
- Hartman, Stephanie M., Andrew J. Barros, and William J. Brady. “The use of a 4-step algorithm in the electrocardiographic diagnosis of ST-segment elevation myocardial infarction by novice interpreters.” The American journal of emergency medicine 30, no. 7 (2012): 1282-1295.
- Mehta, S., F. Fernandez, C. Villagran, A. Frauenfelder, C. Matheus, D. Vieira, M. A. Torres et al. “P1466 Can physicians trust a machine learning algorithm to diagnose ST elevation myocardial infarction?.” European Heart Journal 40, no. Supplement_1 (2019): ehz748-0231.
- Liu, Wenhan, Mengxin Zhang, Yidan Zhang, Yuan Liao, Qijun Huang, Sheng Chang, Hao Wang, and Jin He. “Real-time multilead convolutional neural network for myocardial infarction detection.” IEEE journal of biomedical and health informatics 22, no. 5 (2017): 1434-1444.
- Park, Yeonghyeon, Il Dong Yun, and Si-Hyuck Kang. “Preprocessing method for performance enhancement in cnn-based stemi detection from 12-lead ecg.” IEEE Access 7 (2019): 99964-99977.
- Xiao, Ran, Yuan Xu, Michele M. Pelter, David W. Mortara, and Xiao Hu. “A deep learning approach to examine ischemic ST changes in ambulatory ECG recordings.” AMIA Summits on Translational Science Proceedings 2018 (2018): 256.
- Al-Zaiti, Salah, Lucas Besomi, Zeineb Bouzid, Ziad Faramand, Stephanie Frisch, Christian Martin-Gill, Richard Gregg, Samir Saba, Clifton Callaway, and Ervin Sejdić. “Machine learning-based prediction of acute coronary syndrome using only the pre-hospital 12-lead electrocardiogram.” Nature communications 11, no. 1 (2020): 1-10.
- Wagner, P., Strodthoff, N., Bousseljot, R., Samek, W., & Schaeffter, T. (2020). PTB-XL, a large publicly available electrocardiography dataset (version 1.0.1). PhysioNet. https://doi.org/10.13026/x4td-x982.
- Wagner, P., Strodthoff, N., Bousseljot, R.-D., Kreiseler, D., Lunze, F.I., Samek, W., Schaeffter, T. (2020), PTB-XL: A Large Publicly Available ECG Dataset. Scientific Data. https://doi.org/10.1038/s41597-020-0495-6
- Goldberger, A., Amaral, L., Glass, L., Hausdorff, J., Ivanov, P. C., Mark, R., … & Stanley, H. E. (2000). PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation [Online]. 101 (23), pp. e215–e220.